Я все таки нашел, в чем проблема, но не смог понят с чем это связано.
Вероятно проблема в том, что я чего то недопонимаю, просьба помочь с этим разобраться.
Из основной базы, я сделал экспорт в формате "Выгрузка на сайт в формате E-Trade Series (внеш. модуль)"
Для выгрузки выбрал категорию мониторы.
Создал новую базу.
Импортировал в нее получившийся при экспорте файл.
В новой базе получилась одна категория со всеми имеющимися в ней на данный момент мониторами.
Затем настроил импорт прайса.
Сопоставление везде установил только такое: "Поиск соответствия товаров: с использованием регулярных выражений для категорий товара"
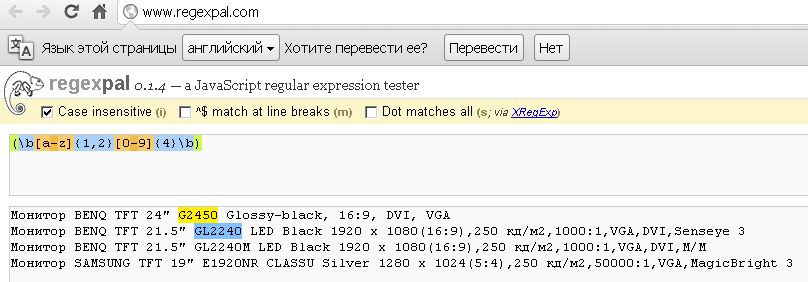
Для категории товара "Мониторы" прописал следующее регулярное выражение: (\b[a-z]{1,2}[0-9]{4}\b) в программе выглядит так:

- 1.jpg (19.72 КБ) 18115 просмотров
Смысл его я понимаю так:
В начале слова должны присутствовать от одной до двух букв латинского алфавита от "a" до "z". Сразу за ними четыре любые цифры. Эти четыре цифры должны быть расположены в конце слова.
Затем я протестировал работу регулярного выражения. Результат получился таким:

- 2.jpg (98.49 КБ) 18115 просмотров
Затем выполнил принудительное сопоставление товаров СТУС и СТИПП, результат которого виден на следующей картинке:
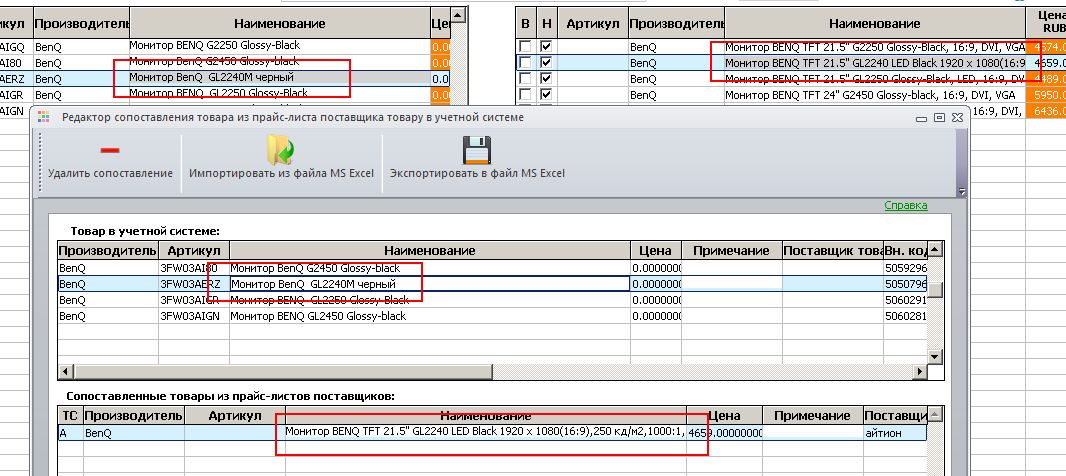
- 3.jpg (129.74 КБ) 18115 просмотров
В итоге получилось, что во время теста результат выражения для товара "Монитор BENQ TFT 21.5"
GL2240 LED Black 1920 x 1080(16:9),250 кд/м2,1000:1,VGA,DVI,Senseye 3"
получился такой:
GL2240
а для товара "Монитор BENQ TFT 21.5"
GL2240M LED Black 1920 x 1080(16:9),250 кд/м2,1000:1,VGA,DVI,M/M", поле в котором должен отображаться результат пустое! Так в общем то и должно быть. А вот при сравнении товары сопоставляются неверно.
Уважаемые разработчики, огромная к Вам просьба помочь мне понять, почему так происходит.
Возможно все дело в метасимволе "\b", который исходя из описания синтаксиса регулярных выражений на этой странице
http://msdn.microsoft.com/ru-ru/library/ae5bf541.aspx - обозначает границу слова. Возможно скобок где то каких то не хватает, и/или последовательность метасимволов неверная. Всю голову себе уже сломал. Помогите пожалуйста разобраться, на конкретном примере. Допустим есть регулярное выражение ([a-z]{1,2}[0-9]{3,4}) каким образом мне нужно его модифицировать, чтобы программа понимала его следующим образом:
1. [a-z]{1,2} - это расположено в начале слова, т.е. спереди стоит пробел или ничего.
2. [0-9]{3,4} - это располагается сразу за указанным, в пункте первом, и за этим стоит либо пробел, либо ничего(т.е. конец строки)
Архив тестовой базу прикрепил к данному сообщению, прайс в стандартной папке, импорт настроен, регулярное выражение прописано, результат можно наблюдать сразу.
Кстати, результат тестирования верный.
- 4.jpg (55.69 КБ) 18115 просмотров




